Software Entropy: A Comprehensive List
Working hard to avoid technical debt is probably the best solution, but it’s likely inevitable that your organization has some. We’ve compiled a relatively comprehensive list of the different types of Technical Debt, or “Software Entropy” that your organization could have or be accumulating.
Examples of technical debt
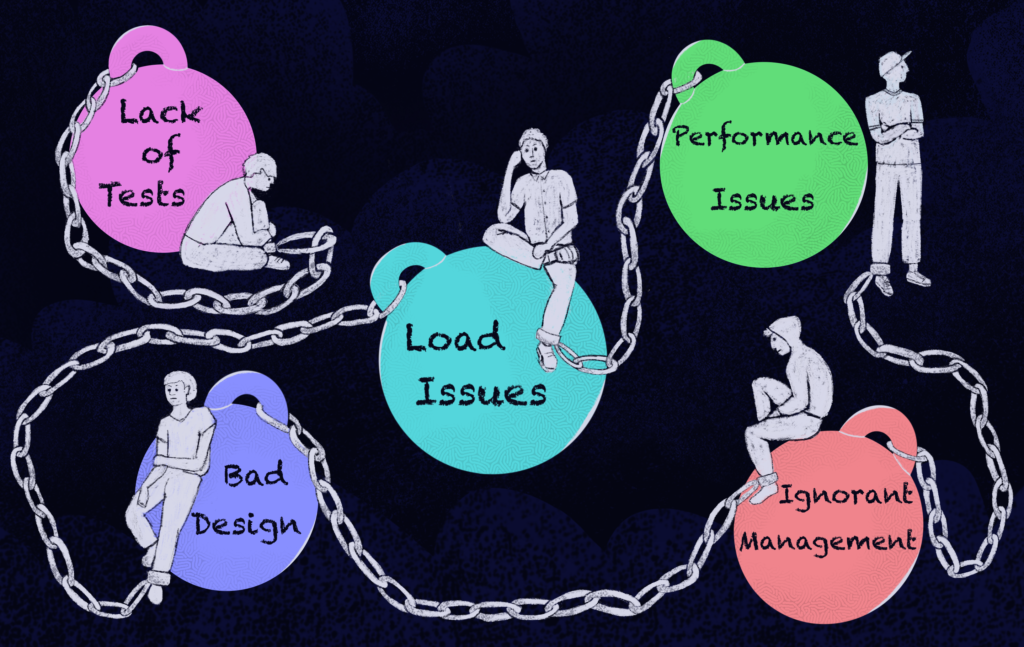
Lack of tests – unit tests, component tests, contract tests, integration tests, end to end tests
Bad design – wrong design decisions initially made (with the information at hand at that point in time). For example, the code is not easily changeable, incidentally complex, high cyclomatic complexity. Mostly due to lack of knowledge and experience, lack of peer review and professional growth mindset, or laziness
Lack of needed documentation – this includes documentation of the code, a setup readme, reasons for changes, the actual product, troubleshooting, and FAQs
Load issues – the system becomes unusable, slow, or requires a lot of memory or computing resources when there are a lot of concurrent users
Performance issues – specific functionality is slow or requires a lot of memory or computing resources
Ignorant management – pressure for features, not allowing quality work or time
Nondeterministic workflows – for example, the order of events is not guaranteed and cannot be relied on
Pending tests – tests that for various reasons are marked to be skipped
Compilation and deprecation warnings – ignoring warnings makes it harder to spot new issues, until things break without notice. There is a reason for these warnings
Manual regression testing as modus operandi – not investing in an automated test suite with reasonable coverage, requires going through slow and expensive manual testing after almost every change we make
Other types of repetitive manual work that could be automated – causing people to do work that a machine could do much at a much lower cost, which would free them to take on higher-level types of work
Bad architecture – not cohesive, too many dependencies, too coupled, not secure enough, doesn’t support required scale, not easily changeable, not reversible, not supporting deferring decisions
Premature optimizations – building things before they are needed, and might not be needed at all, such as scalability or reusability
Immature and unstable libraries – adding immature and unstable libraries, which require frequent mid to large changes as they continue to evolve
Unreadable code – code that is functionally correct and perfectly fine for the machine to execute but is hard for humans to read and change. We read code much more frequently than we write code
Brittleness – certain parts have many bugs, either due to introducing changes or from normal usage of the product
A high number of defects – not enough quality baked in
Outdated workflows – requiring time-consuming workarounds
Tasks that need to be addressed – this includes things like API key rotation
Neglecting specific areas – such as an internal Admin tool
Code inconsistencies – a lack of or inconsistent coding conventions
Out of date elements – Includes languages / frameworks / libraries
Security issues – in the code, in the infrastructure, or in libraries we use
Lack of mechanisms – specifically for detecting security issues
Build Debt – the build process is either manual, or automated but not deterministic, or slow contractors/employees incentivized only by speed
Hero culture – get things done, no matter how it happens
Infrastructure debt – not enough testing environments, not compatible with the needs, no cost optimization
Recurring operational issues or reliability – repeating complaints from customers or from internal users forces developers to handle them in an unplanned manner, repeatedly
Process debt – lack of product discovery (validating what we should build for our users), regular development process (including testing, releasing, and monitoring), disaster recovery, incident management
Requirement debt – requirements that contain contradictions, missing business cases, or UI/UX design
Rollout issues – downtime, breaking things on releases, damage to runtime or data, lack of external communication
Slow to release (low velocity) – processes, technology, or lack of knowledge that makes changes slow to release to the market, making the feedback loop very long
Product complexity & dead features – This also includes features that serve a tiny fraction of the users but have a substantial cost of the development maintenance
GDPR and PII violations – for example, exposing employees to real customers data (Personally Identifiable Information) without justification or giving employees permissions to functionality that they do not need
Tooling debt – tools that don’t support needs, out of date
–
Note: Many organizations use the term “Refactoring” for any technical work, but for precision, it’s worth mentioning that refactoring only refers to changing the code without changing any behavior (usually to make the code more readable or changeable). Bigger initiatives tend to be re-architecture rather than refactoring.
Understanding and managing software entropy
It may seem like software entropy can be found everywhere – and this isn’t entirely false. Avoiding technical debt might sound ideal, but in many cases it is unavoidable. The impacts of technical debt on a company, product, or feature vary greatly.
This is especially true in scenarios where you can gain from implementing something quickly to see how it performs, helping you to decide if it’s something worth putting more time, effort, and resources into.
It’s crucial you understand how to identify your organization’s software entropy, then examine how to manage it. If it can’t be totally avoided, it’s vital to ensure that you are paying it back sooner than later.