
What Modern Data Scientists Should Actually be Doing
Full-stack data scientists are just yet another facet of the AI hype and we don’t need another fancy title for data scientists. What we really need is for data scientists to do data science (which is something very difficult to do, by the way). Supporting this full-stack hype is (1) faulty organizational strategy and (2) critical, but chronically unfulfilled data science-related roles.
In this article, we’ll share our humble opinion on what a Modern Data Scientist should actually care about.
The automation staircase in industry
As our Head of Data Science, Luis Moreira-Matias, clearly stated in the masterclass “AI for Executives” of U. Halmstad (Sweden), there are four steps that you need to take before turning your company into an AI-driven company:
- Digital-Driven: Your processes are digital. Most, or all, employees use electronic devices. The data about your business is fully digital and can be accessed/queried by specialized employees autonomously.
- Data-Driven: Your decisions are data-driven. Every time you make a major decision (hire/fire an employee, invest in a new product, etc.) you do it from cold hard data that you possess and/or collect for the decision-making process. You rely less on the intuition or experience of leaders and, when you do so, you complement it with data.
- Model-Driven: You have Machine Learning/mathematical models in production. They make forecasts, scenarios, and/or suggestions (i.e. Predictive Analytics) that can improve your business. You take the output of these models into consideration for decision-making.
- AI-Driven: You have AI models in production. These models make forecasts and take decisions autonomously. You monitor their performance and their impact on the business closely, but ultimately decisions are driven by machines (i.e. Prescriptive Analytics).
Most organizations struggle with steps 1 and 2 of this process. The main reason for this is that their leaders are not data-aware. They don’t understand the data science development process, the strengths and/or the weaknesses, and how to make a reliable bet on those.
The sense of urgency and the pressure to get results short-term, push them to be more down to Earth – which usually means, never actually being bold enough to take off.
That’s even more true in Europe, where there is a scarcity of venture capital (when compared to the US or China). Therefore, this pushes them to make safer bets on hiring jack-of-all-trades vs. professional Data Scientists.
However, this issue also prevents them from going far and betting realistically on creating an AI-driven business. This is also why you’ve probably worked in that company where you felt that your data science work was making no difference.
Missing roles
Understanding the difference between a Data Scientist and a Data Engineer is relatively straightforward. However, there are 50 shades of grey in the data world — or, more famously among data geeks, 41 shades of blue.
Nowadays, there are a series of new roles, for Production-ready Machine Learning, that are required to both build, and successfully execute, data-driven and AI-driven business strategies. However, most organizations ignore this. We would like to shed light on three of these:
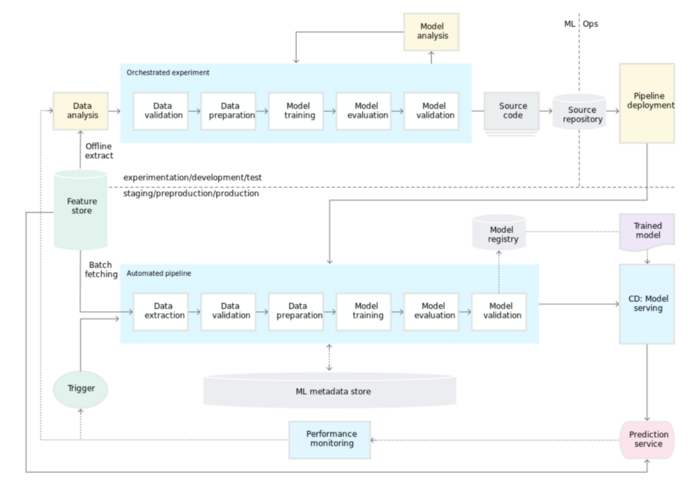
Machine Learning Engineer/MLOps Experts
Many would classify MLOps as a set of practices to enable CI/CD of data science products. While data engineers have to be able to provide API endpoints and/or other ways to feed/collect data from different company services and practices, ML Engineers should be able to support large-scale experimentation, service deployment, and monitoring (i.e collecting ML metadata).
Ideally, these people would be full-fledged software engineers with a lot of knowledge about using the latest cloud technologies, and who would also be experienced in putting ML models in production.
Data Science Product Owner
An Agile Enthusiast that communicates well, understands the big picture but also the DS development process. They can align and prioritize what needs to be done with other teams/stakeholders. In many teams, this role is played by their managers and/or team leader.
Chief Data Officer/Chief Data Strategist/Chief Science Officer
Having a stakeholder at a Senior Leadership level that understands the data science development process is more and more a key success factor for adoption. This person should ultimately decide (together with their peers) on the roadmap for AI in his organization.
They must be knowledgeable — but not necessarily hands-on — about technology and the company’s data, to understand what can be done. But at the same time, should have a strong grasp of the business to understand how to maximize short term impact, maximize adoption of produced artifacts, control the necessary investment and the consequent talent strategy (i.e. how to find/hire/groom/retain exceptional data talent).
What should a (modern) Data Scientist be?
If not end-to-end, the question is: What exactly should a (modern) data scientist be? We’ve summed up the answer into eight bullets:
1. Hands-On
A data scientist may not be end-to-end, but he/she still produces software. Good coding practices (such as documentation, collaborative tools, and testing) have to be there. Experience in production systems is nice-to-have, but not mandatory.
However, let’s be careful to not go to the other extreme: data science is not pure research work. Arguably, you will monetize anything that lives only on a whiteboard. Of course, if you have a breakthrough in your area, it will give your company a competitive edge.
Hence, the bottom line is as follows: Blue sky research has its place in academia and we are not all Einsteins. Doing something tangible that can solve the problem at hand in the near future is the way to go.
2. Expertise
He/She must know his/her stuff. Meaning that he/she understands when to apply the existing methods and how they actually work from a mathematical/statistical/optimization point of view. Today, there is a plethora of online resources to go to for this knowledge…but a good formal training in computer science basics and STEM is a great starting point.

3. Technology Aware
If you are a data scientist currently working in the industry, you are most likely using either R or Python. You have to be aware of the advantages/limitations of these two languages, and when to use one and not the other.
You must be aware of how cloud systems work (basics) and how ML models run in production (What is Docker?). Similarly, it’s expected from a Machine Learning Engineer to know the basic differences between RandomForests and an Artificial Neural Network. Awareness reduces friction.
4. Teamwork
You are a data scientist, but you will work in a multidisciplinary team. Different people, different skill sets, different career paths. You have to be ready to get the best from these people. And that usually happens when you work as a team.
5. Problem Solving Skills
Most data science problems are true puzzles – almost like a research problem that could lead to a Ph.D. thesis (if time and funding allowed it). There is no free lunch formula to solve them nor a single possible optimal solution. You need to be able to both raise and exclude hypotheses, prioritize solution paths and be as exhaustive as time allows on your solution search process.
6. Specialization
Typically, if you want a Data Science team to have an impact, you need to have (at least) three work-streams: (1) Data Science R&D, (2) Data Science Product Owner, and (3) Data Engineer/ML Engineering/MLOps.
As a Data Scientist, you may want to specialize in one of the first two workstreams. If you’re looking to be a great Data Scientist for R&D, you need to pick 1+ DS fields to be really good at out of the following (suggestions):
- NLP
- CV
- Reinforcement Learning
- Predictive Analytics
- Recommendation
- Search
If you’re looking to be a great Product Owner, I recommend you to specialize in an application domain. Some of the most mainstream ones are
- Finance
- Mobility
- Retail/E-commerce
- Healthcare
- Automotive
7. Rigorous Evaluation Protocols
One essential thing is that you know what you’re doing. Another equally important thing is that you know how to demonstrate that you know what you are doing. Evaluation protocols set much of the success or the failure of a data science project in the real world.
Please note, we’re not necessarily only talking about the evaluation metric or the loss function that you use. We’re talking about simulation, large-scale experimentation(e.g.: A/B testing), unit testing, baseline setting, single vs. batch tests, global and local interpretability, post-processing and model threshold selection, in-docker tests, and business awareness (with business-related metrics), p-values, and statistical tests.
When we put all these procedures together, following some application logic to validate a hypothesis, we achieve an evaluation protocol. It’s indispensable that, on receiving requirements for a project, you align upfront with your business stakeholders on what that protocol will be:
What does “success” mean, and how will it be measured?
Typically, business stakeholders will give you a qualitative and ambiguous answer to those questions. To translate that into an evaluation framework with quantitative outputs and targets to those numbers is a task for a data scientist.
To sell that framework back to them as something similar to the answer that you got initially – well, it’s also on the data scientist. Basically, you translate business to tech (Data Science) and then back again. But, “…with great power comes great responsibility”. This brings us to our final point…
8. Storytelling and Communication
Tell me something that I can understand. Data Scientists have to be smart enough to connect the Business Requirements, the Existing Data, and the Available Mathematical Tools/Software Libraries in order to create value. But what must be said next is that they need to be able to explain it as if their audience were 5 years old kids— otherwise, they may be developing solutions that won’t be understood, valued, trusted, or used in practice (example quoted here).
To explain something well, you need to know it better – and to explain complex stuff in simple terms requires a lot of expertise 🙂
Data Scientists need to be doing data science
Learning about data science, maths, optimization, statistics, methods, applications, solutions, advantages, and shortcomings. It requires attention to detail. An ability to learn something fast and to adapt to new problems.
Data Science is not a list of keywords (or a list of tech stacks). Data Science is about connecting the dots. Trying, learning, and failing at things that make sense…something sound from a statistical/mathematical point of view. Data Science is about having the infinite curiosity of asking “what if?” and, at the same time, trying to answer that question.
It’s about doing it better and not simply getting it done. It is about showing that by A+B our solution can add up to X% company revenues. The best way that a data scientist has to add more value to their organization is by doing data science. At least until AutoML takes over Data Sceintits’ jobs completely!

